 PDF(171 KB)
PDF(171 KB)

Moving Average Model with an Alternative GARCH-Type Error
Huafeng ZHU, Xingfa ZHANG, Xin LIANG, Yuan LI
Journal of Systems Science and Information ›› 2018, Vol. 6 ›› Issue (2) : 165-177.
PDF(171 KB)
PDF(171 KB)
Moving Average Model with an Alternative GARCH-Type Error
Motivated by the double autoregressive model with order
moving average model / double autoregressive model / quasi maximum likelihood estimator {{custom_keyword}} /
Table 1 Bias and standard deviations of QMLEs |
| Bias | 0.0148 | 0.0038 | |||
| SD | 0.0229 | 0.0717 | 0.0614 | 0.0712 | |
| AD | 0.0179 | 0.0259 | 0.0481 | 0.0515 | |
| | Bias | 0.0077 | 0.0034 | ||
| | SD | 0.0155 | 0.0535 | 0.0462 | 0.0498 |
| AD | 0.0125 | 0.0213 | 0.0388 | 0.0412 | |
| | Bias | 0.0013 | 0.0243 | ||
| | SD | 0.0537 | 0.0739 | 0.0595 | 0.1082 |
| AD | 0.0548 | 0.0384 | 0.0556 | 0.0680 | |
| | Bias | 0.0011 | 0.0101 | 0.0006 | |
| | SD | 0.0384 | 0.0354 | 0.0390 | 0.0591 |
| AD | 0.0386 | 0.0321 | 0.0395 | 0.0629 | |
| | Bias | 0.0223 | |||
| | SD | 0.0678 | 0.1475 | 0.1108 | 0.0633 |
| AD | 0.0617 | 0.1239 | 0.1071 | 0.0495 | |
| | Bias | 0.0019 | 0.0105 | ||
| | SD | 0.0455 | 0.1078 | 0.0850 | 0.0491 |
| AD | 0.0462 | 0.0840 | 0.0820 | 0.0435 | |
| | Bias | 0.0018 | 0.0217 | ||
| | SD | 0.0385 | 0.1500 | 0.1055 | 0.0539 |
| AD | 0.0359 | 0.1345 | 0.0908 | 0.0400 | |
| Bias | 0.0048 | ||||
| SD | 0.0267 | 0.1020 | 0.0724 | 0.0363 | |
| AD | 0.0245 | 0.0897 | 0.0693 | 0.0204 |
| †Number of replications=1000. |
Table 2 Fitting performance for Models (8)–(9) |
| Model | RMSE for one-step-ahead forecast | Log-likelihood value |
| (8) | 0.0590 | 764.4363 |
| (9) | 0.0583 | 780.5071 |
| 1 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 2 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 3 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 4 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 5 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 6 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 7 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 8 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 9 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 10 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 11 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 12 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 13 |
Li G D, Zhu Q, Liu Z, et al. On mixture double autoregressive time series models. Journal of Business & Economic Statistics, 2015(in press).
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 14 |
Liu F, Li D, Kang X. Sample path properties of an explosive double autoregressive model. Econometric Reviews, 2016(in press).
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 15 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 16 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 17 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 18 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 19 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 20 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 21 |
Billingsley P. Probability and Measure. 3rd Edition, Wiley, New York, NY, USA, 1995.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| {{custom_ref.label}} |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
The authors gratefully acknowledge the Editor and referees for their insightful comments and helpful suggestions that led to a marked improvement of the article.
PDF(171 KB)
 Table 1 Bias and standard deviations of QMLEs
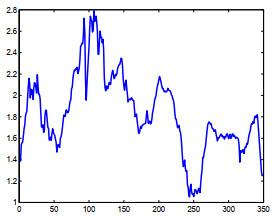
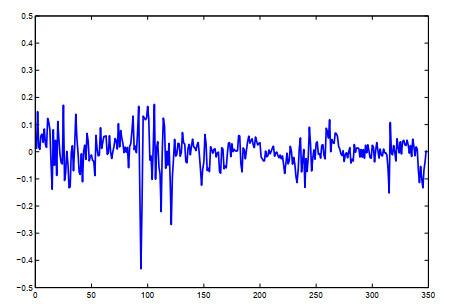
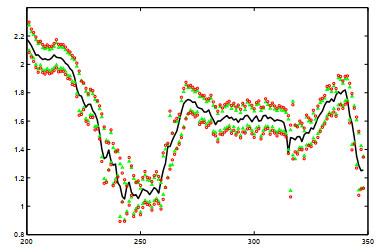
Table 1 Bias and standard deviations of QMLEs Figure 1 Time plot of Figure 2 Time plot of Table 2 Fitting performance for Models (8)–(9)Figure 3 Plot of the data
Figure 1 Time plot of Figure 2 Time plot of Table 2 Fitting performance for Models (8)–(9)Figure 3 Plot of the data /
| 〈 |
|
〉 |




{kind=link}
{kind=link}
{kind=link}