1 Introduction
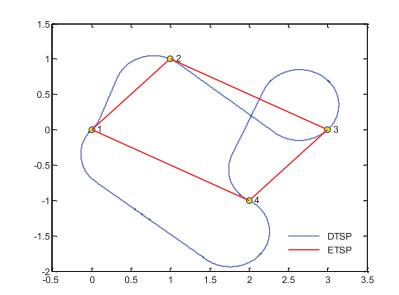
The trajectory of machines like UCAV (unmanned combat aircraft vehicles) or Robots is constrained by their kinematics. A suitable and useful mathematical model is DTSP (Dubins traveling salesman problem). Let be a set of vertices in a plane. The well-known TSP is to find the shortest tour (closed path) visiting every vertex once and only once. Depending on the definition of the distance between any pair of vertices, TSP can be divided into two branches. One is the Euclidean traveling salesman problem (ETSP), in which the distance is defined as the Euclidean distance. The other is the Dubins traveling salesman problem (DTSP), in which the distance is defined as the Dubins distance. See Figure 1: The red line is the tour of ETSP, and the blue dotted line is the DTSP. DTSP differs from ETSP with respect to the constraint on the curvature of the tour; that is, the tour of the DTSP is smooth enough that the tour curvature is limited by , where is the minimal turning radius.
It is well known that the ETSP is NP-complete
[1, 2] and that the DTSP is also NP-complete
[3].
Let ETSP denote the length of the shortest tour of the ETSP over . Correspondingly, let DTSP denote the length of the shortest Dubins tour of the DTSP over with the minimal turning radius . Note that both ETSP and DTSP are in connection with the visiting order, and the optimal ETSP ordering of might be quite different with the optimal DTSP ordering. So, we denote LETSP as the Euclidean distance, and LDTSP as the Dubins distance over with the visiting order . Without confusion, they are abbreviated as LETSP and LDTSP.
If the visiting order is given, then LETSP can be calculated as
but the LDTSP is still not easy to calculate because of unknown optimal headings. Let LDTSP be the Dubins distance with the visiting order and the headings are given. Obviously,
where is the Dubins distance between and , and , .
To calculate
, we can use the famous results given by Dubins in 1957
[4]. Dubins gave a sufficient set of paths (the Dubins set) that always contains the shortest path between any two vertices with given headings. The famous Dubins set is
which includes six admissible paths, where
and
are arcs of the minimal allowed turning radius
turning left or turning right, respectively, and
is a segment. In 2001, Shkel and Lumelsky considered the logical classification scheme, which allows one to extract the shortest path from the Dubins set directly, without explicitly calculating the candidate paths for the 'long path case'
[5]. In [
5], the initial vertex is
, the terminal vertex is
and the radius
.
For DTSP, there are
vertices and cases with any initial and terminal vertices need to be considered. In 2015, Dai and Xie provided the formula to directly calculate the length of the Dubins distance with any initial vertex
, terminal vertex
and minimal turning radius
[6].
Obviously, there are two key problems in the DTSP: Determining the optimal visiting order
and the optimal headings
. The majority of papers focus on the optimal visiting order rather than the optimal headings. Savla, et al.
[7] presented a way to calculate the headings of each vertex, and based on this type of heading, they provided an algorithm called Alternating Algorithm (AA), and they proved that the upper bound of DTSP is
where
. In 2013, Kim and Cheong proved in their paper
[8] that
.
We focus on determining the optimal headings. Note that the fitness of one vertex's head depends on both its own and the neighbor's as well. So, we modeled this problem based on Game Theory, which has received an increasing amount of attention as a promising technique for formulating action strategies for agents in complex situations. The priority of Game Theory in solving control and decision-making problems has been shown in many studies
[9-15].
Finding the Nash Equilibrium in an
-player
game has been proved to be PPAD-complete
[16, 17]. So, the problem of computing Nash Equilibria in games is computationally extremely difficult, if not impossible. But, for a two-player game, it is much easier to solve.
The main contribution of this paper is the development of a game theoretic approach to the DTSP. The headings of vertices are handled from a game theoretic perspective and obtained efficiently by solving the mixed Nash equilibrium of an -player two-strategy game.
The remainder of the paper is organized as follows: Section 2 is the main body of this paper, it describes the Game Theory model for determining better headings and introduces the theory of the Nash Equilibrium. Section 3 concludes our conclusions.
2 Game Theory model
Let be vertices in a plane. Without loss of generality, let the optimal visiting order be . So, there are players in the game. Each player choose it's heading . The heading is seen as a pure strategy in the game. We defined the payoff of player as the Dubins distance between and for all (where ).
The Dubins distance changes greatly with the headings. So, which heading to choose is the key problem. When ranges from to , there is an infinitely pure strategy for each vertex . The problem is difficult to solve because the Dubins distance is not a continuous function.
2.1 Pure Strategies and Payoffs
In this section, we consider the length of the optimal Dubins tour with two vertices. Let be the initial vertex and be the terminal vertex. DTSP denotes the length of the optimal Dubins tour. We have the following Proposition 1, which suggests that there are only two pure strategies that need to be considered for each vertex.
Proposition 1 For two vertices, and ,
(ⅰ) If , .
(ⅱ) If , .
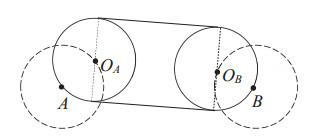
Proof (ⅰ) Based on the Dubins result in 1957, the minimum length between any two vertices must lie in the following Dubins set . By noting that these six types of Dubins paths all start and end with an arc with radius , let and be the center and be the radius; we draw two circles and . See the circles with dotted lines in Figure 2.
Figure 2 The Dubins tour for two vertices with |
Full size|PPT slide
It can be observed that given any arc with radius and which lies on, its center must lie in the circle . This is also the case with . Then, the Dubins tour depends on the position of the center. Without loss of generality, we set the centers as and . See Figure 2. The length of the Dubins tour is . And the minimum length of is .
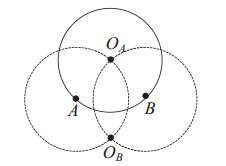
(ⅱ) If , and must intersect at two places. See Figure 3. Let and intersect at and . Then, both and lie in the circle (or ) with radius . So the minimum length of the Dubins tour must not be larger than .
Figure 3 The Dubins tour for two vertices with |
Full size|PPT slide
On the other hand, when we travel from the initial vertex with the minimal turning radius and come back to , the minimal length needed is regardless of whether is visited.
Proposition 1 gives the optimal Dubins tour for two vertices, and it also tells us the optimal headings of initial vertex and of the terminal vertex , that is,
Further, for any initial vertex and terminal vertex , let be the angle of vector . Ihe optimal headings and would be
There are players in the game. Let be the strategy set of then, by Proposition 1, we have
where and are both determined by (3), and is the heading of when is the initial vertex and is the terminal vertex, is determined by is the initial vertex and is the terminal vertex.
The payoff of is defined as
From a game theory point of view, each vertex tries to minimize its own payoff by calculating a pure strategy Nash equilibrium or a mixed Nash Equilibrium. In this way, we get an -players two strategies game.
2.2 Nash Equilibrium
Let be a pure strategy Nash equilibrium, Note that each vertex tries to minimize its own payoff for the length of DTSP, so we have
If player has a pure strategy in a Nash equilibrium, from (5), we need to make comparisons for each .
If player does not have a pure strategy, we need to consider its mixed strategy.
Let be the mixed strategy of player , that is, the heading of vertex is selected with a probability of and is selected with a probability of , where . Let be the mixed Nash equilibrium. We have the following proposition 2.
Proposition 2 Let be the mixed Nash equilibrium, where and , then, for any ,
Proof Since is a mixed Nash equilibrium, we have
Because of , then By the definition of expected payoff,
then by we have
That is,
By Proposition 2, we will get linear equations. The solution of the equations will be the mixed Nash equilibrium.
Above all, we set up a Game Theory model for headings of DTSP. The vertice are the players, and each player has two strategies given by (3), and the payoff defined as (). For the Nash equilibrium, we first discuss whether it has a pure strategy Nash equilibrium. If it does not have a pure strategy for some players, we obtain its mixed strategy from Proposition 2 by solving linear equations.
2.3 An Example
Let be three vertices in a plane and . By (3), we get the strategies of each player ,
The payoffs are as follows:
By the formula of payoff (4), we have Table 1, and from this Table, we know that for all ,
Table 1 Payoff of the three players |
| | | | |
| 8.0035 | 12.9159 | 11.4946 |
| 8.5702 | 13.2317 | 12.3771 |
| 10.0236 | 10.1101 | 6.6687 |
| 10.5903 | 9.9731 | 7.0984 |
| 9.6484 | 13.9813 | 12.0741 |
| 9.9194 | 14.2971 | 12.6609 |
| 11.5113 | 11.0183 | 7.2482 |
| 11.7823 | 10.8813 | 7.3822 |
So, there exists a pure strategy Nash equilibrium . The length of the DTSP is
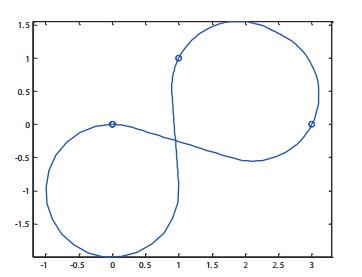
The tour curvature is given in Figure 4.
Figure 4 DTSP with heading given by a pure strategy Nash equilibrium |
Full size|PPT slide
The length of ETSP is , and
So, the length of DTSP with headings given by the Nash equilibrium is much smaller than the upper bound given by (1).
3 Conclusions
In this paper, we study the headings of the DTSP, which is widely used in the field, e.g., UCAV and Robots. It is important to note that we design the headings based on Game Theory. It is the Nash equilibrium that makes our headings quite different.
The simple example in Subsection 2.3 shows that the -player two-strategy Game Theory model provides fairly good headings. In addition, the Nash equilibrium in this model is a pure strategy. The mixed Nash equilibrium can be easily obtained by solving the linear equations given in Proposition 2.
All vertices are in a plane. So, how to determine the headings when the points are located in the three-dimensional space is worth further study. Since any three vertices in a three-dimensional space are coplanar, the presented results in this paper also give a new interesting insight into the three-dimensional DTSP problem.
{{custom_sec.title}}
{{custom_sec.title}}
{{custom_sec.content}}
 PDF(209 KB)
PDF(209 KB)

 Figure 1 ETSP and DTSP
Figure 1 ETSP and DTSP Table 1 Payoff of the three players
Table 1 Payoff of the three players



{kind=link}
{kind=link}
{kind=link}
{kind=link}