 PDF(338 KB)
PDF(338 KB)

A New K-Shell Decomposition Method for Identifying Influential Spreaders of Epidemics on Community Networks
Kai GONG, Li KANG
Journal of Systems Science and Information ›› 2018, Vol. 6 ›› Issue (4) : 366-375.
PDF(338 KB)
PDF(338 KB)
A New K-Shell Decomposition Method for Identifying Influential Spreaders of Epidemics on Community Networks
An efficient method for the identification of influential spreaders that could be used to control epidemics within populations would be of considerable importance. Generally, populations are characterized by its community structures and by the heterogeneous distributions of out-leaving links among nodes bridging over communities. A new method for community networks capable of identifying influential spreaders that accelerate the spread of disease is here proposed. In this method, influential spreaders serve as target nodes. This is based on the idea that, in k-shell decomposition method, out-leaving links and inner links are processed separately. The method was used on empirical networks constructed from online social networks, and results indicated that this method is more accurate. Its effectiveness stems from the patterns of connectivity among neighbors, and it successfully identified the important nodes. In addition, the performance of the method remained robust even when there were errors in the structure of the network.
complex networks / community structure / k-shell decomposition / influential spreaders {{custom_keyword}} /
Table 1 Structural properties of networks |
| Network | N | E | < k > | kmax | < d > | C | r | H | G | Q |
| Caltech | 571 | 7127 | 24.96 | 96 | 2.96 | 0.57 | 0.01 | 0.36 | 9 | 0.79 |
| Princeton | 3975 | 23457 | 11.80 | 129 | 4.721 | 0.32 | 0.41 | 0.43 | 30 | 0.74 |
| Georgetown | 6309 | 73022 | 23.14 | 311 | 4.21 | 0.25 | 0.24 | 0.45 | 16 | 0.68 |
| Oklahoma | 6850 | 152985 | 44.66 | 247 | 4.36 | 0.52 | 0.48 | 0.51 | 42 | 0.92 |
| 1 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 2 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 3 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 4 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 5 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 6 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 7 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 8 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 9 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 10 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 11 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 12 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 13 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 14 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 15 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 16 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 17 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 18 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 19 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 20 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 21 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 22 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 23 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 24 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 25 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 26 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 27 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 28 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 29 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 30 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 31 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 32 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 33 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| {{custom_ref.label}} |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
PDF(338 KB)
 Table 1 Structural properties of networks
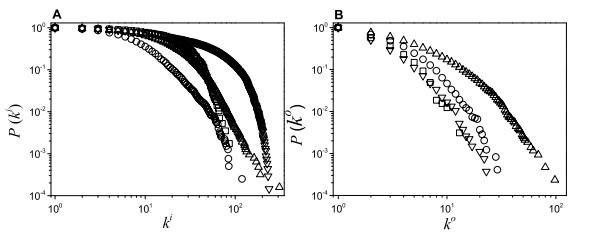
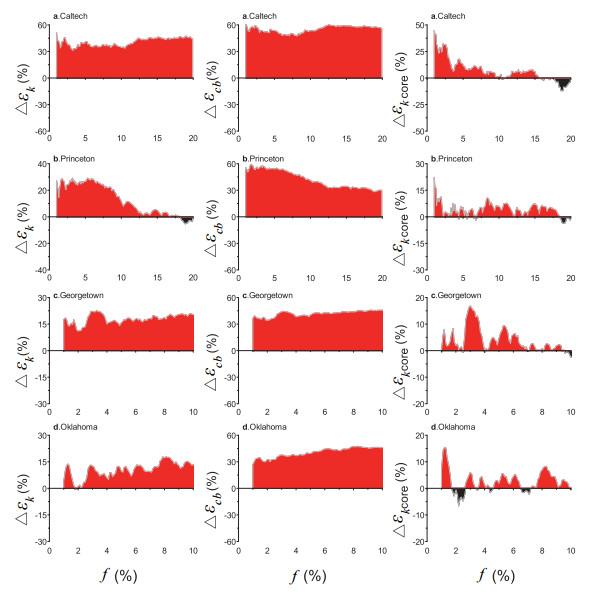
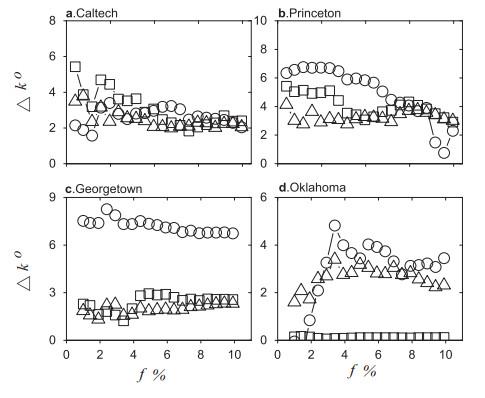
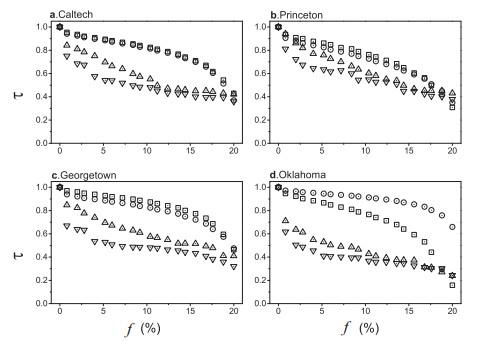
Table 1 Structural properties of networks Figure 1 Cumulative distribution of out-leaving links and inner links in empirical networksFigure 2 Comparison of spreading efficiency of identification in empirical networksFigure 3 Comparison of average out-leaving links among neighbors of nodes identified by Figure 4 Robustness of the methods in networks with noise as modeled by random removal of connections
Figure 1 Cumulative distribution of out-leaving links and inner links in empirical networksFigure 2 Comparison of spreading efficiency of identification in empirical networksFigure 3 Comparison of average out-leaving links among neighbors of nodes identified by Figure 4 Robustness of the methods in networks with noise as modeled by random removal of connections/
| 〈 |
|
〉 |




{kind=link}
{kind=link}
{kind=link}
{kind=link}