1 Introduction
With the development of network technologies, more and more service industries perform task assignment based on crowdsourcing
[1]. In this mode, instead of assigning tasks to fixed employees, task publishers assign tasks according to certain rules based on the current situation. For the task publisher, this model can quickly find a large amount of available labor and expand the scope of services; for the employee, this model simplifies the process of finding a job and can gain some benefits. Compared with the traditional stable employment relationship, crowdsourcing task assignment shortens the employment cycle and increases the frequency of employment, and thus the game between task publishers and employees becomes more complicated. In the process of task assignment, crowdsourcing task assignment should consider both improving employee satisfaction to achieve employee retention and enhancing the vested profit of task publishers
[2].
First, in the context of the deep integration of the Internet and big finance, the competition among various task publishing platforms has gradually evolved into cultivating users' "loyalty" to the platform
[3]. In this process, retaining employees and ensuring the quality and durability of their services are more and more important to task publishers. Therefore, task publishers should focus on maintaining employee satisfaction. Furthermore, profit is the primary goal of task publishers in the task distribution process. However, there is a natural trade-off between task publisher's profit and employee satisfaction, which is further complicated by factors such as the quality of task completion
[4].
In the case of a takeaway platform, for example, the task publisher assigns orders to employees and receives a certain amount of profit from the merchant. In order to get more profit, both the task publisher and the employee want to get more orders. However, when an employee takes multiple order at the same time, the completion quality of each order may be affected, e.g., during the delivery process, the latter orders may cause users to negatively comment on the platform due to overtime, resulting in loss of profit. To ensure profits and service quality, task publishers should take into account the reliability of employees in completing tasks when assigning tasks. At the same time, employee satisfaction is influenced by subjective interest and objective access to rewards. Since the total profit of each task is fixed, there is a game between task publishers and employees in the distribution of profits
[5].
As tasks are continuously assigned, the reliability and satisfaction of employees are constantly changing; at the same time, task publisher have to balance vested interests and future interests for long-term development. Therefore, the current task assignment is not isolated, but is influenced by the results of past task assignments, which also affects the future task assignments. To this end, this paper studies the crowdsourcing task assignment problem based on task publishers' net profit and employee satisfaction. To describe the situation of employees undertaking tasks, the reliability and interest of employees are modeled, and quantitative mathematical expressions for task publisher net profit and employee satisfaction are given based on
[6]. A multi-objective optimization problem
[7] is constructed to maximize task publisher net profit and employee satisfaction by jointly optimizing the task assignment matrix and task offer vector. Since the considered problem contains discrete variables, it cannot be solved directly by traditional optimization methods. For this reason, two low-complexity algorithms are proposed in this paper. The first algorithm is a search method constructed based on a fast non-dominated ranking genetic algorithm with an elite strategy
[8] to inscribe the Pareto optimality bound of the considered problem
[9]. The second algorithm is a weighted single objective function optimization algorithm constructed based on a reinforcement learning framework
[10]. Numerical results show that the number of tasks undertaken by each employee affects both employee satisfaction and employer net profit, and that employers should set the maximum number of tasks to be undertaken according to the employee profile. The numerical results also give Pareto optimal bounds and Pareto optimal solutions based on the solutions of the two proposed algorithms, which quantitatively characterize the tradeoff between employer net profit and employee satisfaction.
2 Model Description
Consider a typical crowdsourcing task assignment model, where a task publisher (later referred to as an "employer") is expected to complete different types of tasks. For this purpose, the employer, through the task publishing platform, assigns tasks to employees. Both tasks and employees are considered as heterogeneous, i.e., the characteristics of the tasks are different, and the competencies possessed by employee are also different. Each employee can be assigned to more than one task, but not more than at most, and each task is assigned to only one employee. This is common in take-out and delivery platforms when assigning tasks, for example, a rider can often deliver multiple orders at once, but each order will not be delivered by multiple riders. When assigning tasks, the employer gives a quotation for each task, and the th task quotation is recorded as . The quoted price will not exceed the profit available for completing the task, i.e., . Depending on the completion of the task, the employee will be paid accordingly, up to an upper limit of . At the same time, the employer may also receive a commission, i.e., net profit, for this task, up to a maximum of .
In order to characterize the situation of employees undertaking tasks, each employee possesses two basic attributes, namely reliability and interest, defined as follows.
1) Employee Reliability. Facing the th task, the reliability of the employee's reliability is denoted as to indicate the employee's completion of the task, and the range of values is where means incomplete and indicates perfect completion. Since the task completion degree directly affects the task profit, the actual payoff for the th employee to complete the th task is and the net profit to the employer is .
The characterization of employee reliability is an important issue in crowdsourcing task assignment. In this paper, the current reliability of employees is characterized based on the historical reliability and the current number of tasks, which is expressed as
where is a random number generated by normal distribution with a mean value of and variance of 1, and satisfying both and . denotes the coefficient of the number of tasks for the th employee. When is larger, it indicates that the reliability of the employee is more affected by the number of tasks. denotes the number of tasks currently assigned to the th employee. It is worth noting that the mean value of will be updated with the completion degree and number of completions of the task by the employee. When the task completion degree is high, the average value of increases to 1; conversely, the average value of decreases to 0. For each employee, the reward for completing tasks is related to both the number of tasks and the reliability. Therefore, the employer should take both into account when assigning tasks, avoiding both low pay due to a low number of tasks assigned to the employee and a decrease in the employee's reliability rating due to a high number of tasks assigned to the employee.
2) Employee interest. Faced with the th task, the th interest of the employee is expressed as , which is used to indicate the subjective willingness of the employee to take up the task, and the value range is , where indicates that the employee does not want to undertake the task, and indicates a perfect desire to undertake the task. The interest is mainly influenced by the historical interest level and the current quotations, which is expressed as
where is a random number generated by normal distribution with a mean value of and a variance of , and satisfies both and . It is also worth noting that the mean and variance of will be updated with the number of times the employee completes the task, and the employee's interest in a certain task will decrease as the number of times increases. Employers need to motivate employees by increasing the quotation.
When assigning tasks, the main indicators that employers need to consider are net profit and employee satisfaction, both of which are related to the reliability and interest of employee, as defined below.
1) Employer net profit. As mentioned above, the employer earns a net profit from the difference between the profit after the completion and the quoted price of the task. Assign tasks, the total net profit obtained is
where is the task assignment factor and takes the value . When , it means that the th task is assigned to the th employee; when , it means that the th task is not assigned to the th employee. Therefore, the number of tasks assigned to th employee can be expressed as
2) Employee satisfaction. Employee satisfaction is mainly determined by their interest in completing tasks and the payoff they receive, expressed as
where denotes the interest degree weighting coefficient, and denotes the payoff weight coefficient and satisfies .
For employers, current net profit represents short-term benefits, while employee satisfaction represents long-term benefits, both of which are important. If the employer only focuses on completing the short-term benefits currently obtained, the employee will be poached by other task publishing platforms due to dissatisfaction with the job. This is common in Internet platforms such as takeaway, taxi, delivery, etc. Therefore, employers need to consider the current net profit and employee satisfaction when assigning tasks. In addition, there are some trade-offs in the task assignment process, for example, employees tend to get more tasks and thus more pay, but when an employee is assigned too many tasks, its completion of each task will be influenced, so employers need to balance the trade-off between employees' demands and task completion. The more employees are assigned the same type of task, the better they are at completing the task, but the lower their interest in the task. Therefore, employers need to balance the trade-off between employee interest and task completion. These relationships increase the complexity of problem analysis and solution, but also provide a broad scope for exploration.
3 Question Construction
In this paper, we consider the interests of employers and employees, and design a crowdsourcing task assignment mechanism to jointly maximize employers' profits and employees' satisfaction as the goal to achieve the best match between employees and tasks.
Let denote the task assignment matrix, and denote the offer vector, the multi-objective optimization problem under consideration can be modeled as
where constraint (C1) indicates that each task has and is only assigned to one user; constraint (C2) indicates that the total number of tasks shared by each user does not exceed . constraint (C3) means that the offer of each task must not be higher than the task profit.
At the end of a batch, the employee's reliability and interest in the task will change, so when the next batch arrives, the employer will reassign the task based on the updated employee reliability and interest.
4 Solving Method
The problem under consideration is a multi-objective optimization problem and there is a trade-off between two objectives that are constrained to each other, i.e., the increase in the employer's total net profit/employer's satisfaction is at the cost of employee satisfaction/employer's total net profit. In addition, the problem under consideration has discrete variables (i.e., task assignment matrix) that are difficult to solve directly using traditional gradient solving methods (e.g., convex optimization theory). Given that task assignment problems are often large in scale and the task assignment process is demanding for time delay, this paper proposes two low-complexity solution methods based on genetic algorithms and reinforcement learning algorithms, respectively.
Both genetic algorithms and reinforcement learning algorithms can handle large-scale task assignment problems, and they are both non-gradient algorithms that can handle discrete variables or discontinuous functions. In contrast, the genetic algorithm can handle the considered problem and find the Pareto optimal solution without configuring hyperparameters, but when the reliability and interest of employees change, it needs to be calculated again; reinforcement learning requires multiple hyperparameters and multiple training episodes, and for the trained model, even if the reliability and interest of employees change, it can be directly derived from the constructed deep neural network. In general, genetic algorithms are better for single processing; reinforcement learning algorithms are better for long-term processing.
4.1 Genetic Algorithm-Based Task Assignment Method
The genetic algorithm simulates the biological evolution process by maintaining potential solutions from generation to generation and gradually approximating the optimal solution of the problem through population computation and stochastic search. The algorithm does not require prior background knowledge of the problem or additional hyperparameter settings, and is well adapted to problems of complex form and large size. Among many genetic algorithms, the fast and elitist non-dominated sorting generic algorithm (NSGA-II) with elitist strategy is considered as an effective method to solve multi-objective optimization problems, which can locate the Pareto optimal solution set of the problem under consideration.
For the problem under consideration, the feasible domain is defined as
For a feasible solution , if there is no , such that and hold simultaneously, then we claim is a Pareto-optimal solution to the problem under consideration, and that dominate .
NSGA-II performs fast non-inferiority ranking based on the dominance relationship between feasible solutions to improve search efficiency and algorithm robustness. The core steps are summarized as follows.
1) Encoding and decoding. For the problem under consideration, the task assignment matrix of each element takes the value of binary, i.e., 0 or 1, so no additional encoding is required. However, since the quote vector is a continuous variable, each element of is first discretized and then binary encoded. The value of the quotation of the th task is and the value of each quote is binary encoding, denoted as . The binary quote vector composed of is denoted as . Combine all the quotes that satisfy the constraints , , and of the task assignment matrix and the encoded quotes form a genetic population set denoted as . When calculating the objective function value, it is necessary to is recovered after decoding as .
2) Generation of the initial population. Based on the set of constructed gene populations, feasible solutions are randomly selected from and recorded as individuals to form the initial population. Subsequently, the population is continuously updated by the selection mechanism, and the number of individuals in the population remains to be .
3) Fast non-dominated sorting. To speed up the search, the population is stratified according to the level of individual non-inferiority solutions. For the th individual in the population, calculate the number of individuals that dominate individual and the set of individuals dominated by individual . On this basis, a fast non-inferiority stratification is performed, and the specific steps are: a) Find the individuals in the population of the population, i.e., the individuals that are not dominated by any other individuals, and save them to the current set ; b) For each individual in the set , iterate through each individuals in the set of the individuals it dominates, execute and saves to the set of individuals , i.e., find the individuals other than individual which is not dominated by any other individual except individual ; c) The individual obtained in the set is the first non-dominated individual in the stratum with . The above steps are repeated until the whole population is stratified.
4) Virtual fitness. Keeping the diversity of individuals in the population can avoid too much stacking of feasible solutions in local optimum. For this reason, virtual fitness is proposed in NSGA-II. The specific steps are: a) Initialize the distance between individuals in the same layer, so that ; b) To the individuals in the same stratum by the first objective function values in ascending order; c) Make the individuals on the edge of the ranking have the selection advantage, and ; d) For the individuals in the sort, find the crowding distance ; e) Repeat the above steps for different function values.
5) Selection operator. The selection operator improves the survival probability of high-performance individuals and reduces the loss of effective genes, which in turn optimizes the direction toward the Pareto optimal solution and makes the solution more homogeneous. Based on the non-dominated ordering and crowding distance calculation, each individual in the population has two properties, i.e., non-dominated ordering and crowding distance. A round-robin selection operator is used to randomly select two individuals, and when two individuals have different non-dominated rankings, the individual with the lower ranking (i.e., less dominated) is selected; when two individuals have the same non-dominated ranking, the individual with the less crowded surrounding is selected.
6) Crossover and variation. The algorithm's local and global search performance is improved by changing the value of the last set of feasible solutions through crossover variation. For example, using simulated binary crossover (SBC), given a random crossover point, the parts of two parent individuals located on either side of the crossover point are exchanged.
7) Elite strategy. To prevent the loss of excellent solutions during random evolution, an elite retention mechanism is added. That is, an additional archive set is constructed to save the elite individuals searched during the evolution of the population, while the individuals in the archive set do not evolve directly. Due to the limitation of computational and storage resources, the archive set needs to be updated according to the Pareto relationship between the saved individuals and the individuals in the evolved population.
The process of solving the considered problem based on NSGA-II is summarized in the following algorithm.
| Algorithm 1 NSGA-II-based task assignment method |
Input: maximum number of genetic iterations, deviation of fitness function, population size, i.e., number of feasible solutions generated each time, optimal front-end individual coefficient ParetoFraction ∈ (0, 1).
Output: Task allocation strategy
1: Set NI=100, randomly generate a set of feasible solution sets
2: for iterations less than the maximum number of genetic iterations do
3: Evolutionary population (crossover and variation), by changing the values of the previous set of feasible solutions through crossover variation to obtain a new set of feasible solutions
4: Perform fast non-dominated sorting
5: Calculating virtual fitness
6: Implement elite strategies to retain NI a viable solution
7: Based on this set of feasible solutions, calculate the current results of the two objective functions ,
8: End For
9: End While |
4.2 Reinforcement Learning Based Task Assignment Method
The multi-objective optimization problem can be transformed into a weighted single-objective optimization problem. Restricted by the choice of weight coefficients, compared with direct multi-objective optimization, weighted single-objective optimization will have some loss in optimality. However, solving the weighted single-objective optimization problem by reinforcement learning algorithm can greatly improve the efficiency of task assignment, adapt to the changing environment, and make rapid adjustments to task assignment.
The problem of optimizing task assignment based on crowdsourcing can be modeled as a Markov decision process (MDP) based problem, and such problems are suitable for solving using the -learning algorithm. The core of -learning is to build a -table containing all state-action pairs, and the learning process of -learning can be considered as a function approximation of state-action pairs, i.e., a function approximation of values. Each value in the table indicates how good or bad an action is taken by the agent in the current state, and the agent updates the values in the table through continuous interaction with the environment. When it is known that the intelligent body is in a certain state, the action that has the maximized value is selected as the action to be executed in the current state, and the value is updated by the following formula
where denotes the learning rate of the algorithm; denotes the immediate reward of the environment after the agent performs action a in state; denotes the discount factor; and denotes the next state after the agent performs the action . Thus, this Q-learning algorithm can be defined as a quadratic Markov process , where denotes the state space; denotes the action space; denotes the reward function; and denotes the probability of state transfer (which can be ignored when the model is determined).
In reinforcement learning, traditional -leaning algorithms have some limitations. For example, -learning uses a -table to store states and actions, and when there are many states-actions, the -table becomes very complex and too dimensional, which consumes a lot of time and memory space to find and store. In addition, in a crowdsourcing-based task assignment environment, a large number of tasks and multiple users are usually generated. In this case, a large number of actions are generated, and traditional -learning algorithms are clearly not applicable. For this reason, Deep Network (DQN) combines -learning with neural network to improve the -learning algorithm, which can effectively solve such defects of traditional -learning algorithm that cannot handle high-dimensional data, when the -value update formula is as follows.
In crowdsourcing tasks with a high number of states and actions, it is more appropriate to use DQN for solving them. In the model of DQN, the platform observes the environment state to assign appropriate tasks; the execution effect of these tasks (employee satisfaction, employer net profit, etc.) is fed back to the platform as reward values, and the platform again learns to assign tasks based on these choices and reward values to complete the training process of the model. The core of the work lies in 1) designing the corresponding action space and state space for the research content; 2) modeling the research content into a Markov decision process and 3) designing a suitable reward function.
1) Action space The action of the task assignment platform consists of a task assignment matrix and a representation offer vector . Since the action space of the value-based DQN algorithm must be finite, in the proposed DQN-based algorithm, the task assignment matrix and the discretized offer vector as the set of feasible actions. Where, for the offer vector , which is in the range of 0 to is divided into equal parts, we define the set
indicates an optional offer.
2) State space For the design of the state space, the following three points are considered: 1) Whether each task has and is assigned to only one user (constraint C1); 2) Whether the total number of tasks allocated to each user does not exceed (constraint C2); and 3) the action selection in the current state. Based on this, note that is the set of states, and for the th employee, at the -th iteration, define its state to be
where denotes whether it is satisfied at the -th iteration that each task has and is assigned to only one employee, defined as follows:
Similarly, indicates whether the total number of tasks allocated to each employee does not exceed , which is defined as
Also, indicates the action selection in the current state.
3) Reward function The reward function is the goal of the platform for task assignment. The degree of good or bad strategy of learning is essentially determined by the reward function, and only by designing the correct reward function can the platform achieve the purpose of learning through continuous iteration. In the task assignment process, each employee's task assignment has an impact on other users, and the satisfaction and profit generation of all employees jointly influence the effect of task assignment. Therefore, the reward function needs to jointly consider the objective of the optimization problem as well as the constraints.
For the optimization objective, the higher the employer's net profit, the higher the value of the reward function, and vice versa. Similarly, the higher the employee satisfaction, the higher the value of the reward function, and vice versa. For ease of processing, a weighted single objective function is used to represent the multi-objective function. The weighted sum of employer net profit and employee satisfaction can be directly considered as the reward function, which is given by
where and denotes the balance coefficient between total employee profit and employee satisfaction.
For the constraint, when each task is assigned to one user and only one user, the agent will receive a positive reward and vice versa with a larger penalty. Similarly, when the total number of tasks allocated to each user does not exceed , the agent will also receive a positive reward, and vice versa. Thus, the constraint is expressed as
where denotes the reward or punishment received by the agent under whether the constraint is satisfied or not. When the constraints (C1) and (C2) are not satisfied, the reward will drop sharply. Conversely, when the constraint is satisfied, the agent receives a positive reward. That is, maximization implies that constraints (C1) and (C2) can be satisfied. Therefore, the reward function is defined as
where and are the weight values to balance the rewards of the optimization objective and its constraints. Through the above construction of action space, state space, and reward function in this section, a DQN-based task assignment method is proposed, and the pseudo-code of this algorithm is as follows.
| Algorithm 2 DQN-based task assignment algorithm |
1: Initialize various parameters
2: while each round of iterations do
3: for each intelligent body do
4: Initialization state
5: while each time slot do
6: Generate a random number between 0 and 1 rand(0, 1)
7: if rand(0, 1) then
8: Randomly select an action in the action set
9: else
10: Select the action with the maximum Q value in the current state
11: EndIf
12: #160; Execute the action , get an immediate return , and get the next state
13: Deposit the experience gained into the experience pool
14: Random sampling of small batches from the experience pool
15: Update the Q value according to the X equation
16: Switching states, i.e.,
17: if Current Iteration Number Maximum number of iterations then
18: Execute Step 3
19: else
20: Jump out judgment
21: Endif
22: EndFor
23: EndWhile |
5 Simulation Results
Consider a typical crowdsourcing task assignment model. The number of tasks posted by the employer is set to 10, the profit of each task is set to 10, and the offer is divided into 10 level, i.e., the of profit. The number of employees is set to 5, and the reliability and interest of employees for each task are randomly generated. Both the interest degree weighting factor and the payoff weighting factor are set to 0.5. The maximum number of tasks that each employee can undertake is set to 5. For the above values, there are a total of 9454621 task assignment matrices satisfying the constraints and a total of offer vectors. Therefore, there are more than 9.4 task assignment option. If we use the exhaustive method to traverse all task assignment options, we need to consume huge computational resources, and it is difficult to guarantee the timeliness of task assignment. The proposed two algorithms can significantly improve the task assignment efficiency and have the ability to adapt to the changes of user reliability and interest.
1) Maximum number of employee assignments versus employer net profit
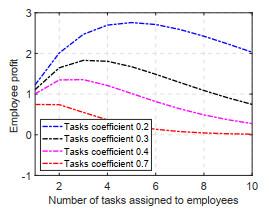
Figure 1 plots the relationship between the number of tasks assigned to employees and employee profit. It can be seen that the optimal number of tasks to be assigned varies at different task quantity coefficients and the trend of variation is also different. For example, when the task quantity coefficient is 0.7, it means that the employee's reliability is influenced by the task quantity, so the employee profit decreases monotonically with the number of tasks undertaken. For example, when the number of tasks coefficient is 0.2, 0.3 and 0.4, the employee profit increases and then decreases with the number of tasks undertaken, and there is an optimal number of tasks undertaken. This result is consistent with real-life situations, such as when employees take on too many tasks, there is often a decline in the completion of individual tasks. Therefore, employers should set the maximum number of tasks to be undertaken according to employee characteristics when assigning tasks in order to obtain the maximum profit.
Figure 1 Relationship between the number of tasks assigned to employees and employee profit |
Full size|PPT slide
2) Maximum number of tasks undertaken by employees and employee satisfaction
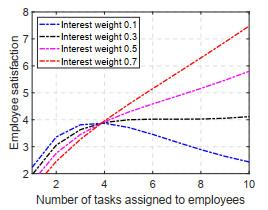
Figures 2 and 3 plot the relationship between the number of tasks assigned to employees and employee satisfaction with offer accounts being 40% and 80% of the profit, respectively. Employee satisfaction is generally higher when the offer accounts for a higher percentage, while employee satisfaction is more likely to be influenced by the amount of tasks undertaken by employees. This is because when the offer is high, employee compensation is the dominant factor in employee satisfaction, and when the amount of tasks undertaken by employees increases, the reliability of completing each task decreases, resulting in a decrease in the actual compensation received, and thus satisfaction is more likely to be influenced by the amount of tasks undertaken. On the contrary, when the offer is low, the interest of the employees increases in the satisfaction and is less influenced by the reward received. In addition, the weight of employees' interest in the task is also an important factor in the change of satisfaction and the number of tasks undertaken. The higher the interest weight of employees, the more stable the trend of satisfaction with the number of tasks undertaken. This shows that for employers, a single reliance on raising the task offer can improve employee satisfaction, but it is not conducive to stabilizing employee satisfaction, and cultivating employee interest in the task assignment process.
Figure 2 The relationship between the number of tasks assigned to employees and employee satisfaction (quoted as 80% of profit) |
Full size|PPT slide
Figure 3 Relationship between the number of tasks assigned to employees and employee satisfaction (quoted 40% of profit) |
Full size|PPT slide
3) Employee Satisfaction and Employer Net Profit Pareto Boundary
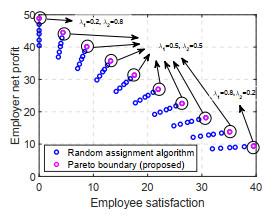
Figure 4 gives the Pareto boundaries for employee satisfaction and employer net profit. The compromise relationship between employee satisfaction and employer net profit is affected by profit distribution, and the effect of the number of tasks undertaken by employees on employee satisfaction and employer net profit makes the compromise relationship more complex. According to the proposed genetic algorithm the satisfaction-net profit domain can be carved out, and a larger satisfaction-net profit domain can be obtained compared to the random assignment algorithm. When using the reinforcement learning algorithm, the multi-optimization objective is changed to the weighted values of employer net profit and employee satisfaction, and thus the obtained results are related to the choice of weighting coefficients. With different weighting factors, the reinforcement learning algorithm can obtain different results on the Pareto boundary.
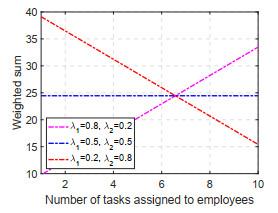
Figure 5 plots the results obtained by the reinforcement learning algorithm for different weighting factors. As mentioned earlier, the crowdsourcing task assignment problem includes task assignment matrix and task offer, which generate feasible solutions of great order of magnitude. While genetic algorithms can search for different Pareto solutions by discrete populations, reinforcement learning algorithms provide low-complexity solution algorithms. It is worth stating that the reinforcement learning algorithm performs dynamic online task assignment because of the variation in employee reliability and interest considered by the reinforcement learning algorithm.
Figure 5 Weighted sum of employer net profit and employee satisfaction |
Full size|PPT slide
6 Summary
In this paper, we study the crowdsourcing task assignment problem and construct a multi-objective optimization problem to maximize employer net profit and employee satisfaction by jointly optimizing the task assignment matrix and the task offer vector. Since the problem under consideration contains discrete variables, it cannot be solved using convex optimization theory. For this reason, two low-complexity, high-performance algorithms are proposed in this paper. The first algorithm is a search method based on NSGA-II construction, which inscribes the Pareto optimality bound of the considered problem. The second one is a weighted single objective function solution algorithm based on reinforcement learning. Numerical results show that the number of tasks undertaken by each employee affects both employee satisfaction and employer net profit, and that employers should set the maximum number of tasks undertaken according to the employee profile. The numerical results also give Pareto optimal bounds and Pareto optimal solutions based on the two proposed algorithms, which quantitatively characterize the tradeoff between employer net profit and employee satisfaction.
To further improve the efficiency of task assignment, an algorithmic framework for generating labeled data with the help of genetic algorithms and then computing them through supervised learning will be investigated in the future.
{{custom_sec.title}}
{{custom_sec.title}}
{{custom_sec.content}}
 PDF(163 KB)
PDF(163 KB)

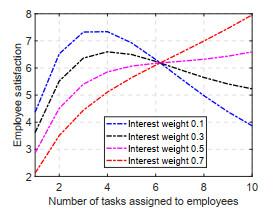

 Figure 1 Relationship between the number of tasks assigned to employees and employee profit
Figure 1 Relationship between the number of tasks assigned to employees and employee profit



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}